
Your robots.txt file is one of the most powerful — and most misunderstood — files on your website. Get it wrong and you can accidentally deindex your entire site. Get it right and you save crawl budget and keep private pages private.
What Is robots.txt?
robots.txt is a plain text file at your site root at yoursite.com/robots.txt. It tells search engine crawlers which pages to crawl or skip, following the Robots Exclusion Protocol — a voluntary standard followed by Googlebot, Bingbot, and DuckDuckBot.
Important: robots.txt controls crawling, not indexing. A blocked page can still appear in search results if other sites link to it. Use a noindex meta tag to prevent indexing.
Common robots.txt Rules
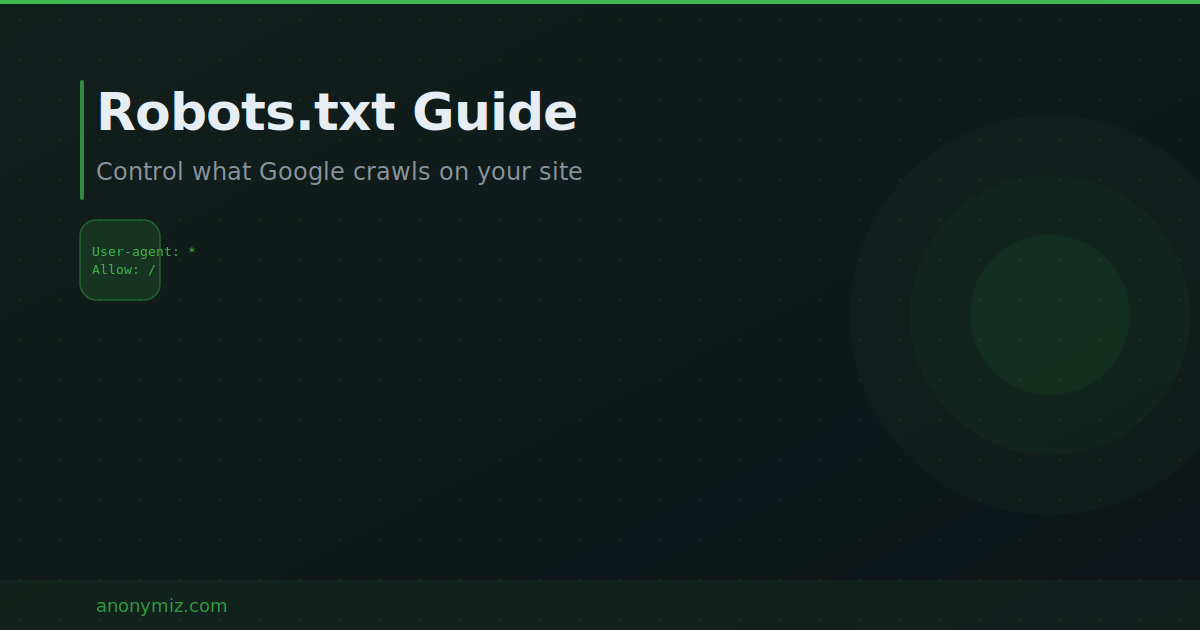
To allow everything: set User-agent to * and Allow to / and include your Sitemap URL. To block a directory: set Disallow to /admin/ or /private/. To block AI training bots like GPTBot: set User-agent to GPTBot and Disallow to / then repeat for other AI crawlers.
Common Mistakes to Avoid
- Blocking CSS and JavaScript — Googlebot needs to render your pages to understand them
- Using robots.txt for sensitive data — it is a public file anyone can read
- Forgetting the Sitemap line — include it to help crawlers discover all your pages
- Case errors — /Admin/ and /admin/ are treated as different paths
Generate Your robots.txt Free
Use the Anonymiz Robots.txt Generator to build a valid file without memorizing syntax. Choose directories to block, add your sitemap URL, and download the ready-to-upload file in seconds.


